
Semantic Hub Hypothese: LLMs denken in einer gemeinsamen Sprache
Im Dezember 2025 veröffentlichten Forscher des MIT, der University of Southern California und des Allen Institute for AI eine Studie, die zeigt, dass moderne Sprachmodelle eine gemeinsame Bedeutungsstruktur über verschiedene Sprachen und Datenformate hinweg nutzen. Dieses Prinzip, bekannt als die „Semantic Hub Hypothese“, besagt, dass KI-Modelle ähnliche Begriffe und Konzepte in einer gemeinsamen Repräsentation speichern, unabhängig davon, ob sie als Text, Bild, Audio oder Code vorliegen.
Die Untersuchung ergab, dass das Modell semantisch äquivalente Inhalte in verschiedenen Sprachen in seinen Zwischenschichten ähnlich verarbeitet. Diese Gemeinsamkeiten erstrecken sich nicht nur auf Sprachen, sondern auch auf mathematische Ausdrücke, Programmcode sowie visuelle und akustische Daten. Veränderungen in dieser gemeinsamen Struktur beeinflussen vorhersagbar die Modelloutputs in anderen Datentypen, was darauf hindeutet, dass diese Repräsentationsstruktur aktiv genutzt wird und nicht nur ein zufälliges Nebenprodukt des Trainings ist.
Diese Erkenntnisse eröffnen neue Perspektiven für die Entwicklung von KI-Systemen, die in der Lage sind, über verschiedene Modalitäten hinweg zu generalisieren und zu interagieren.
Wie LLMs verschiedene Datentypen gemeinsam verarbeiten
Moderne Sprach- und multimodale Modelle (LLMs) sind in der Lage, verschiedene Datentypen wie Texte in unterschiedlichen Sprachen, Code, mathematische Ausdrücke sowie visuelle und auditive Eingaben zu verarbeiten. Die Frage ist, wie diese Modelle mit so unterschiedlichen Daten umgehen, obwohl sie mit denselben Parametern arbeiten. Eine mögliche Strategie besteht darin, für jeden Datentyp separate Bereiche zu lernen, die nur für diesen bestimmten Datentyp verwendet werden. In vielen Fällen jedoch teilen verschiedene Datentypen grundlegende, semantische Konzepte. Dies ist besonders deutlich bei Sätzen in verschiedenen Sprachen, die dieselbe Bedeutung haben. Ähnliche gemeinsame Konzepte existieren auch bei anderen Datentypen, zum Beispiel zwischen einem Bild und seiner Beschreibung oder zwischen einem Code und seiner natürlichen Sprachbeschreibung.
Das menschliche Gehirn besitzt eine „semantische Drehscheibe“, die Informationen aus verschiedenen Sinnesbereichen (wie Sehen und Hören) integriert und speichert. Ein Modell könnte diese strukturellen Ähnlichkeiten nutzen, um die Oberflächenformen unterschiedlicher Datentypen in einen gemeinsamen Bereich zu projizieren, dort Berechnungen durchzuführen und diese dann wieder in die jeweilige Datentyp-Form zurückzuführen.
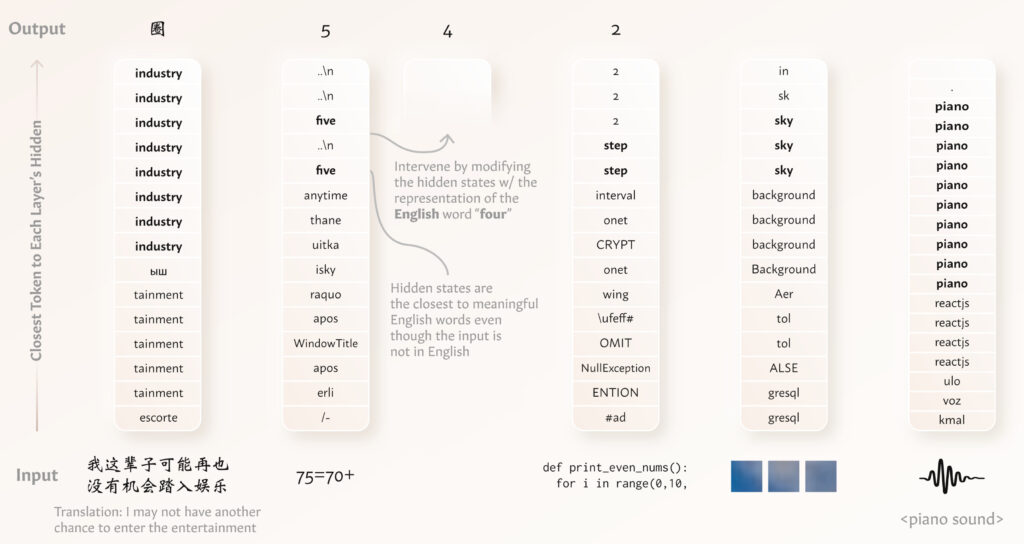
Studien zeigen, dass Modelle wie Llama-2 mehrere Datentypen in einem gemeinsamen Bereich repräsentieren. Zum Beispiel verarbeitet das Modell chinesischen Text, indem es zunächst auf das englische Modell zugreift und danach den Text zurück in die chinesische Form übersetzt. Dieser „semantische Hub“ ist ein gemeinsamer Raum für verschiedene Datentypen, der vor allem durch den dominanten Datentyp (meist Englisch) geprägt wird. Es wurde zudem nachgewiesen, dass Eingriffe in diesen gemeinsamen Raum Auswirkungen auf die Modell-Ausgabe haben, wenn andere Datentypen verarbeitet werden.
Unsere Forschung zeigt, dass Modelle, die mit verschiedenen Datentypen trainiert wurden, diese in einem gemeinsamen Raum verarbeiten, ohne dass eine explizite Anpassung erforderlich ist. Diese Erkenntnisse erleichtern das Verständnis der Funktionsweise moderner LLMs und bieten wertvolle Einblicke für die gezielte Steuerung und Verbesserung dieser Modelle in der Zukunft.
Wie genau sieht der semantische Hub in LLMs aus?
Moderne Sprachmodelle (LMs) verarbeiten verschiedene Arten von Daten wie Texte in verschiedenen Sprachen, Bilder oder sogar mathematische Ausdrücke. Diese Daten kommen aus verschiedenen „Modi“ (z. B. Text, Bild, Ton), aber das Modell muss sie alle in einem gemeinsamen Raum verstehen können. Um das zu tun, stellen wir uns vor, dass es einen „gemeinsamen semantischen Hub“ gibt, einen Raum, in dem ähnliche Bedeutungen von verschiedenen Datenarten zusammengefasst werden.
Zum Beispiel, wenn ein Modell einen Text in Chinesisch verarbeitet, könnte es diesen Text zuerst in einem gemeinsamen Raum abbilden, als ob der Text in Englisch wäre, und dann den passenden Fortsetzungsbegriff in Englisch finden. Die Idee ist, dass das Modell lernt, dass Texte in verschiedenen Sprachen oder sogar von verschiedenen Datentypen ähnliche Bedeutungen haben und sie in diesem gemeinsamen Raum verarbeitet.
Das Modell nutzt einen bevorzugten Datentyp (z. B. Englisch für Llama-2) und verankert den Raum in diesem Typ. So kann es den „Hub“ in einer Weise verstehen, die es ihm erlaubt, den Text richtig fortzusetzen, egal ob der Text ursprünglich in einer anderen Sprache oder einem anderen Datentyp vorliegt. Zum Beispiel wird der chinesische Text „这篇论文太难“ (was „Dieses Papier ist so schwer“ bedeutet) eher mit dem englischen Wort „write“ (statt mit der chinesischen Übersetzung „写“) verbunden, da Englisch der bevorzugte Datentyp für das Modell ist.
Kurz gesagt: Das Modell nutzt den gemeinsamen semantischen Raum, um verschiedene Arten von Daten zu verbinden, sodass es ähnliche Bedeutungen über verschiedene Modi hinweg erkennen kann.
Unser Takeaway
Die neue Studie bestätigt die „semantische Hub“-Hypothese, die besagt, dass Sprachmodelle semantisch ähnliche Eingaben aus unterschiedlichen Quellen in ihren mittleren Schichten nahe beieinander darstellen. Diese Erkenntnis zeigt, wie Sprachmodelle verschiedene Datenarten effizient verarbeiten, und bestätigt, dass Modelle oft am besten auf Englisch arbeiten. Gleichzeitig wirft die Studie wichtige Fragen auf, etwa die potenziellen Probleme der Abhängigkeit von einer dominanten Sprache und der Herausforderung, mathematische Ausdrücke in natürlicher Sprache zu verarbeiten.
- LLMs denken meist in einer bevorzugten Sprache (oft Englisch).
- Alle Eingaben werden zunächst in diese Sprache übersetzt und danach zurückübersetzt.
- Unabhängig vom Dateiformat erfolgt die Verarbeitung immer nach diesem Prinzip.
Best Practice
- Klare und einfache Sprache verwendem – Schreibe klar, direkt und präzise, um die Verständlichkeit und Übersetzbarkeit zu verbessern.
- Englische Inhalte priorisieren oder optimieren – Wenn möglich, stelle hochwertige englische Inhalte bereit. Andernfalls achte darauf, dass Übersetzungen maschinenfreundlich formuliert sind und klare, standardisierte Begriffe verwenden, die in vielen Sprachen eindeutig sind.
- Strukturierte Daten und Metadaten nutzen – Verwende Schema.org-Markup, um deine Inhalte maschinenlesbar zu gestalten, und setze auf eine saubere HTML-Struktur mit klaren Überschriften und Abschnitten. Achte zudem darauf, aussagekräftige Dateinamen, Alt-Texte und Metabeschreibungen zu nutzen, um die Auffindbarkeit und Verständlichkeit deiner Seite zu verbessern.
- Konsistente Begriffe und Formatierungen wählen – Verwende für wiederkehrende Begriffe und Konzepte immer dieselben Formulierungen, um Klarheit und Konsistenz zu gewährleisten. Vermeide kreative Wortspiele oder unübliche Schreibweisen, die schwer übersetzbar sind, und halte numerische Werte sowie Einheiten standardisiert, zum Beispiel durch die Verwendung von Zahlen anstelle ausgeschriebener Ziffern, wenn es nicht unbedingt erforderlich ist.