Explorative Analyse von Verkaufsdaten (EDA)
Über den Datensatz
Für dieses Projekt habe ich den fiktiven, aber realitätsnahen E-Commerce-Datensatz „sales_data_sample“ analysiert. Er enthält Bestelldaten eines internationalen Unternehmens, das hochwertige Miniaturmodelle und Sammlerfahrzeuge verkauft – von Motorrädern und Oldtimern bis hin zu Flugzeugen und anderen Modellfahrzeugen. Die Daten stammen aus einer MySQL-Datenbank und umfassen über 2.800 Transaktionen.
Im Datensatz finden sich wichtige Informationen wie Bestellnummern, Verkaufszahlen, Preise, Produktlinien, Kundendaten und Zeitstempel auf Monats- und Jahresbasis.
Was wird analysiert?
Ich untersuche hier das Verkaufsverhalten des Online-Shops, um wertvolle Einblicke und Trends zu entdecken. Visualisiert mit Python und Seaborn zeige ich, wie sich Umsatz und Bestellungen über Zeit, Regionen und Produkttypen entwickeln.
Ziel des Projekts
Mein Fokus liegt darauf, folgende Fragen zu beantworten:
Wann werden die meisten Bestellungen getätigt?
Welche Produktlinien sind besonders umsatzstark?
Welche Regionen erzielen die höchsten Umsätze?
Gibt es saisonale Muster oder Wachstumspotenziale?
Diese Erkenntnisse helfen dabei, datenbasierte Entscheidungen für Marketing, Vertrieb und Lagerplanung zu treffen.
Erster Überblick
| Order | Date | Customer | Product | Qty | Price | Sales | Status | Country | Deal Size |
|---|---|---|---|---|---|---|---|---|---|
| 10107 | 24/02/2003 | Land of Toys Inc. | S10_1678 | 30 | 95.70 | 2871.00 | Shipped | USA | Small |
| 10121 | 07/05/2003 | Reims Collectables | S10_1678 | 34 | 81.35 | 2765.90 | Shipped | France | Small |
| 10134 | 01/07/2003 | Lyon Souveniers | S10_1678 | 41 | 94.74 | 3884.34 | Shipped | France | Medium |
| 10145 | 25/08/2003 | Toys4GrownUps.com | S10_1678 | 45 | 83.26 | 3746.70 | Shipped | USA | Medium |
| 10159 | 10/10/2003 | Corporate Gift Ideas Co. | S10_1678 | 49 | 100.00 | 5205.27 | Shipped | USA | Medium |
Gib hier deine Überschrift ein
Unten sehen Sie eine vereinfachte Darstellung der wichtigsten Attribute unserer Daten mit entsprechenden Erklärungen:
Order Number – Eindeutige Bestellnummer
Quantity Ordered – Bestellte Menge
Price Each – Einzelpreis pro Produkt
Order Line Number – Position der Bestellung innerhalb der Gesamtbestellung
Sales – Gesamtumsatz (Menge × Einzelpreis)
Order Date – Datum der Bestellung
Status – Aktueller Bestellstatus (z. B. Shipped, Cancelled)
Quarter ID (QTR_ID) – Zugehöriges Quartal (1–4)
Month ID – Monat der Bestellung (1–12)
Year ID – Jahr der Bestellung
Product Line – Kategorie oder Produktlinie (z. B. Motorcycles)
MSRP – Unverbindliche Preisempfehlung des Herstellers
Product Code – Eindeutige Produktkennung
Customer Name – Name des Kunden oder Unternehmens
Phone – Telefonnummer
Address Line 1 – Hauptanschrift
Address Line 2 – Zusätzliche Adressinformationen
City – Stadt
State – Bundesstaat oder Region (sofern vorhanden)
Postal Code – Postleitzahl
Country – Land
Territory – Vertriebsgebiet
Contact Last Name – Nachname der Kontaktperson
Contact First Name – Vorname der Kontaktperson
Deal Size – Größenkategorie des Geschäfts (z. B. Small, Medium, Large)
Erste Insights:
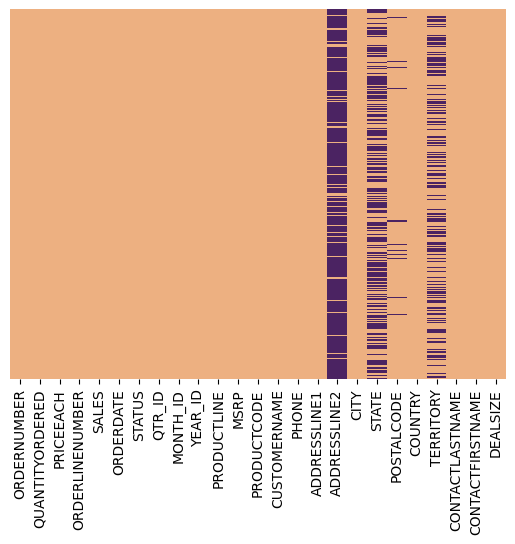
Wir haben insgesamt 2.823 einzelne Datenpunkte über 25 Spalten hinweg analysiert. Davon sind 20 Spalten vollständig ausgefüllt, während 5 Spalten teilweise fehlende Werte aufweisen. Bezogen auf den gesamten Datensatz entspricht dies etwa 7,3 % fehlender Daten.
Besonders auffällig ist, dass es sich bei den fehlenden Werten hauptsächlich um ortsbezogene Attribute handelt. So fehlen beispielsweise in der Spalte Address Line 2 nahezu 90 % der Werte. Dies ist jedoch weniger problematisch, da diese Spalte meist ergänzende Informationen wie Gebäudeteile oder Stiegen enthält.
Auch die Spalten State und Territory können vernachlässigt werden, da wir in der Regel auf den Postal Code zurückgreifen können, der die Region meist genauer beschreibt. In diesen relevanteren Spalten liegen nur etwa 2,7 % fehlende Daten vor, die wir bei regionalen Auswertungen später einfach entfernen oder ersetzen können. Für die weitere Bearbeitung können wir also Attribute ADDRESLINE2, STATE und TERRITORY droppen
| Spalte | Fehlende Werte (%) |
|---|---|
| Addressline 2 | 89.30 |
| State | 52.64 |
| Postal code | 2.69 |
| Territory | 38.04 |
Cleaned Data
Da alle Attribute – mit Ausnahme der ortsbezogenen Felder – vollständig vorliegen, können wir den Datensatz zunächst so belassen. Die Spalten AddressLine2, State und Territory sind weitgehend irrelevant und können daher direkt entfernt werden.
Anschließend wandeln wir YEAR_ID und MONTH_ID mithilfe von pd.to_datetime in ein sinnvolles Zeitformat um, um zeitbasierte Auswertungen zu ermöglichen.
Nun können wir mit den ersten inhaltlichen Analysen beginnen.
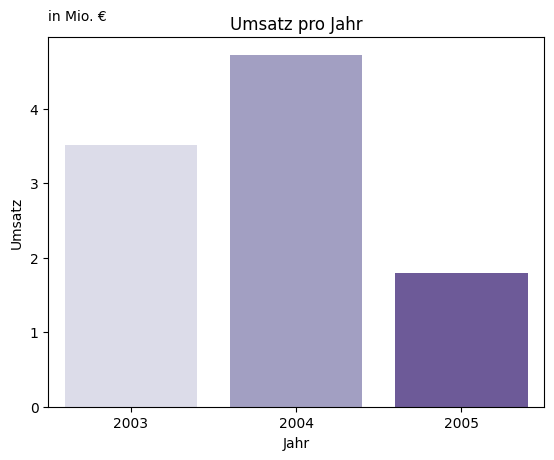
Umsatz
Werfen wir einen Blick auf den Umsatz der einzelnen Jahre. Wir können sehen, dass der Umsatz von 2003 auf 2004 von 3.516.979,54 € auf 4.724.162,60 € steigt. Das entspricht einer Steigerung von genau 34,32 %. Allerdings fällt der Umsatz im Jahr 2005 wieder um 62,08 % im Vergleich zu 2004 ab. Woher kommt dieser starke Umsatzrückgang? Schauen wir uns die einzelnen Jahre genauer an.
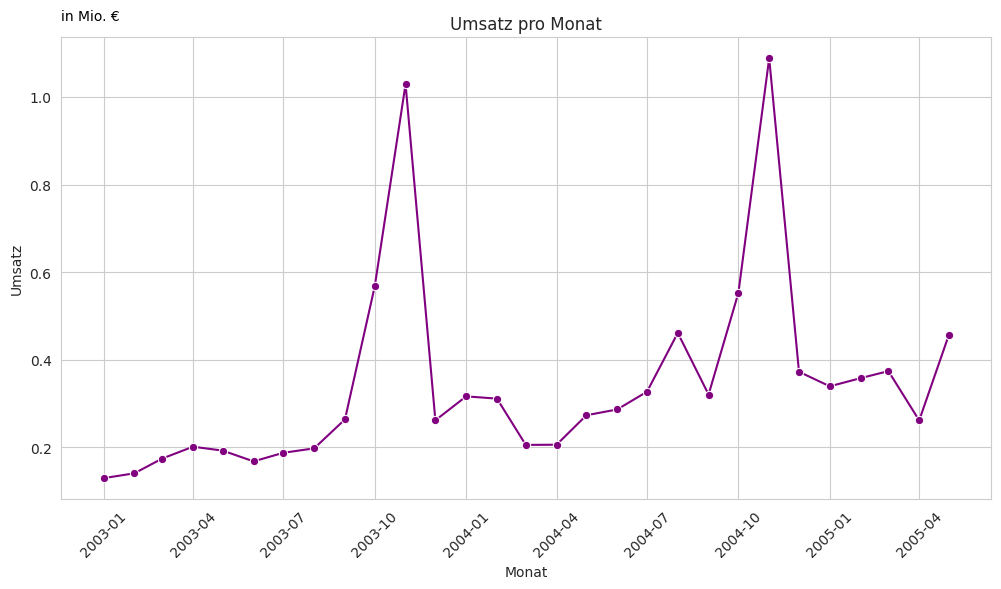
Umsatz pro Monat
Wenn wir uns die monatlichen Umsätze ansehen, erkennen wir, dass der November in beiden Jahren besonders stark ausfällt. 2003 lag der Umsatz bei 1.029.837,66 €, während er 2004 auf 1.089.048,01 € anstieg. Das entspricht einer Steigerung von rund 5,75 % im Vergleich zum November des Vorjahres.
Auffällig ist außerdem, dass die Daten für das Jahr 2005 lediglich bis einschließlich Mai vorliegen. Dadurch ist ein vollständiger Vergleich des Gesamtjahres 2005 mit den Vorjahren nicht direkt möglich, was auch den insgesamt niedrigeren Jahresumsatz in diesem Jahr erklärt.